Пока инструмент проходит внутреннее тестирование, но уже может с точностью до 98% определить изображения, сгенерированные при помощи DALL-E 3. Но это касается только картинок, которые после создания ИИ дополнительно не обрабатывались.
Система не так успешно работает, если созданную ИИ картинку обрезать или отредактировать каким-то другим способом. В OpenAI собираются привлечь сторонних тестеров, чтобы повысить эффективность работы инструментария.
Компания рассматривает идею о платном доступе к "премиальным" функциям поиска на основе искусственного интеллекта.
Согласно отчету Financial Times, компания намерена ввести платную версию своего поисковика с ИИ-функциями. Примечательно, что в отчете указывается, что даже при наличии подписки пользователи продолжат видеть рекламу.
С чего все началось:
С появлением ChatGPT от OpenAI в ноябре 2022 года, который умеет давать быстрые и полные ответы, традиционный поиск с его списками ссылок и рекламой оказался под угрозой. Google не мог остаться в стороне и начал эксперименты с ИИ, чтобы предложить что-то новенькое: более глубокие и детализированные ответы на ваши запросы.
В мае Google начал тестировать экспериментальную поисковую службу на основе ии, предоставляя более подробные ответы на запросы, продолжая при этом предоставлять пользователям ссылки на дополнительную информацию и рекламу.
Но вот незадача – все это требует гораздо больше вычислительных ресурсов 🙄 Да и люди стали меньше обращать внимание на рекламу и переходить по ссылкам, зачем, ведь им итак дают исчерпывающие ответы, а это не очень нравится рекламодателям и бьет по карману💸
В итоге деньги откуда-то надо брать, и Google думает добавить расширенные функции ИИ-поиска в свои премиальные службы подписки, которые уже предлагают доступ к новому помощнику Gemini AI в Gmail и Docs.
При этом традиционная поисковая система Google останется бесплатной для всех.
Пока руководство Google не приняло окончательное решение о запуске премиального поиска.
Нормально они свою бизнес-модель переделывают, да? 😐
Если вам интересны новые технологии, полезные сервисы и новости будущего, добро пожаловать в ИИшница 🍳 - пища для ума в мире высоких технологий
Представьте, что вы смотрите музыкальный клип, в котором каждая сцена, каждый персонаж и каждое движение камеры созданы искусственным интеллектом. Звучит как научная фантастика? Что ж, будущее уже наступило. Встречайте The Hardest Part - первый в истории музыкальный клип, полностью сгенерированный нейросетью Sora от OpenAI.
Этот новаторский проект - плод совместных усилий инди-музыканта Washed Out (настоящее имя - Эрнест Грин) и режиссера Пола Трилло. Клип на песню “The Hardest Part” демонстрирует впечатляющие возможности генеративных моделей в создании реалистичных и захватывающих визуальных образов. Но как именно работает эта технология, и какое влияние она окажет на индустрию развлечений? Давайте разберемся.
Под капотом Sora: Как нейросеть создает видео
Примечание: Следующее описание основано на рассуждениях Итана Хи (Ethan He), исследователя ИИ из NVIDIA, бывшего сотрудника FAIR и выпускника CMU, с более чем 6000 цитирований и 5000 звезд на GitHub. Оригинальная статья доступна на LinkedIn Pulse. Реальные технологии являются коммерческой тайной OpenAI и еще не были обнародованы.
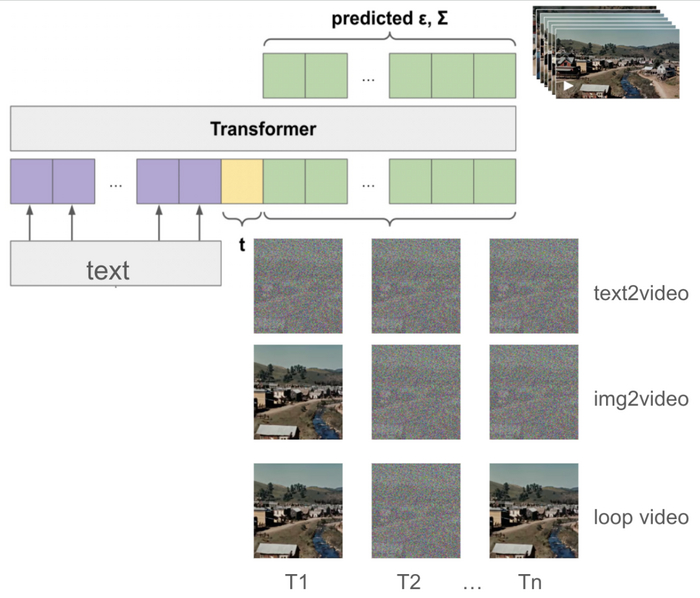
Предполагается, что в основе Sora лежит DiT (диффузионный трансформер) - архитектура, которая использует возможности масштабирования трансформеров наряду с итеративным процессом уточнения диффузионных моделей, я уже рассказывал про AnimateDiff, который позволяет генерировать видео на моделях Stable Diffusion, тут этот принцип многократно улучшен.
Схема работы диффузионного трансформера
Трансформеры известны своей эффективностью в обработке последовательных данных и обеспечивают надежную архитектуру для моделирования временной динамики видео. Процесс диффузии, в свою очередь, итеративно уточняет выходные данные, начиная с зашумленного начального состояния и двигаясь к желаемому видеовыходу, повышая качество и согласованность сгенерированных видео.
Для сжатия видео Sora использует векторный квантованный вариационный автоэнкодер (VQ-VAE) на основе трехмерной сверточной нейронной сети (3D CNN). Эта архитектура сети состоит из энкодера, который уменьшает размерность визуальных данных до скрытого пространства, и декодера, который реконструирует видео из этого сжатого представления.
Схема работы VQ-VAE для сжатия видео
Использование 3D CNN позволяет захватывать временную динамику видео, что важно для создания согласованного и плавного движения в сгенерированных клипах. Симметричная конструкция энкодера и декодера обеспечивает эффективное сжатие и реконструкцию видео, сохраняя высокую точность исходного контента.
Процесс обучения Sora
Во время обучения к видеотокенам добавляется случайный шум. Трансформер получает на вход текстовое условие, временной шаг диффузии и зашумленные видеотокены.
Генерация текста в видео
Универсальность Sora распространяется на различные приложения, включая анимацию статических изображений и создание идеально зацикленных видео. Анимация статического изображения достигается путем кодирования изображения как первого токена и использования шума для остальных токенов. Для создания бесшовно зацикленных видео Sora обеспечивает идентичность первого и последнего токенов на каждом шаге диффузии, улучшая эстетическую привлекательность сгенерированного контента.
Генерация видео из изображения
Одним из самых замечательных аспектов Sora является ее способность демонстрировать такие возникающие возможности, как 3D-согласованность и постоянство объектов, без явного программирования. Традиционно для достижения 3D-согласованности в сгенерированных видео требовались специальные функции потерь. Однако Sora показывает, что при масштабировании эти возможности могут возникать естественным образом, позволяя генерировать видео, точно имитирующие реальную динамику и взаимодействия.
Таким образом, Sora представляет собой значительный скачок в области генерации видео с помощью ИИ, объединяя несколько передовых технологий для создания высококачественных видеороликов из текстовых описаний.
Создание клипа “The Hardest Part”: Сложности и уроки
Несмотря на впечатляющий результат, процесс создания клипа The Hardest Part с помощью Sora был далеко не простым. Режиссеру Полу Трилло пришлось сгенерировать более 700 видеофрагментов, чтобы отобрать из них 55 лучших для финального клипа. Каждый фрагмент требовал детального текстового описания, учитывающего не только визуальные элементы, но и движения камеры, ракурсы и действия персонажей.
Без динамики сцены смотрятся откровенно странно
“Мы пролетаем сквозь пузырь, он лопается, мы пролетаем сквозь жвачку и выходим на открытое футбольное поле”, - так Трилло описывал одну из сцен клипа.
Пока у Пола Трилло был доступ к Сора он так же сделал промо заставку для TED Talks, со столь полюбившимися ему пролетами камеры. Как по мне, получилось интереснее чем в клипе.
Этот опыт показывает, что даже с использованием передовых алгоритмов ИИ создание качественного видеоконтента требует значительных усилий и творческого подхода. Сора, безусловно, открывает новые возможности, но она не заменяет человеческий талант, а дополняет его.
Барьеры на пути к массовому использованию
Несмотря на огромный потенциал Sora и подобных технологий, их широкое применение в индустрии развлечений пока сталкивается с рядом препятствий. Главным из них является высокая стоимость генерации видео.
Для создания согласованных и реалистичных видеопоследовательностей Sora требуется огромное количество вычислительных ресурсов и объем памяти. По оценкам экспертов, генерация даже короткого клипа может обходиться в сотни или тысячи долларов. Для сравнения, другие мультимодальные модели, такие как LLaVA и CogVLM, которые работают только с изображениями и текстом, уже требуют существенных затрат на GPU и электроэнергию.
Еще одним барьером является вопрос авторских прав и интеллектуальной собственности. Модели вроде Sora обучаются на огромных массивах видеоданных, принадлежащих различным правообладателям и в том числе открытых. Использование сгенерированного ИИ контента в коммерческих проектах может привести к юридическим спорам и конфликтам интересов.
OpenAI и Голливуд: Стратегия внедрения
Сгенерированный Сэм Альтмен на фоне сгенерированных голливудских холмов
OpenAI, разработчик Sora, активно продвигает свою технологию в киноиндустрии. В марте 2024 года генеральный директор компании Сэм Альтман и другие представители провели серию встреч с голливудскими студиями, режиссерами и продюсерами. Цель этих встреч - найти партнеров для дальнейшего развития и внедрения Sora в кинопроизводство.
Для крупных киностудий использование генеративных моделей может означать существенное сокращение затрат на производство визуальных эффектов и ускорение процесса создания фильмов. OpenAI рассчитывает, что партнерство с Голливудом поможет не только улучшить Sora, но и продемонстрировать ее возможности широкой аудитории.
Однако не все в киноиндустрии разделяют энтузиазм по поводу внедрения ИИ. Многие актеры, режиссеры и другие творческие работники опасаются, что генеративные модели могут лишить их работы и нивелировать ценность человеческого таланта. Поэтому OpenAI предстоит найти баланс между технологическим прогрессом и интересами профессионального сообщества.
Sora и будущее развлечений
Первый музыкальный клип, созданный с помощью Sora, - это лишь начало большого пути. По мере развития генеративных моделей и снижения стоимости их использования, мы увидим все больше примеров применения ИИ в киноиндустрии, музыке, видеоиграх и других сферах развлечений.
Однако важно помнить, что технологии вроде Sora - это инструменты, а не замена человеческого творчества. Они открывают новые горизонты и позволяют воплощать самые смелые идеи, но за каждым успешным проектом по-прежнему стоят талантливые люди - режиссеры, сценаристы, художники и многие другие.
Будущее индустрии развлечений - это симбиоз творчества и технологий, в котором ИИ дополняет и усиливает человеческие способности. И клип “The Hardest Part” - это лишь первый шаг на пути к этому будущему.
А что вы думаете о потенциале генеративных моделей вроде Sora? Как они повлияют на индустрию развлечений и творческие профессии? Поделитесь своим мнением в комментариях!
Я рассказываю больше о нейросетях у себя на YouTube, в Телеграм и на Бусти. Буду рад вашей подписке и поддержке. Всех обнял.
Выспаться, провести генеральную уборку, посмотреть все новые сериалы и позаниматься спортом. Потом расстроиться, что время прошло зря. Есть альтернатива: сесть за руль и махнуть в путешествие. Как минимум, его вы всегда будете вспоминать с улыбкой. Собрали несколько нестандартных маршрутов.
Снова эксперимент, на этот раз новости еще короче, буквально несколько предложений. Пусть будет quick news.
1 В Fallout 3 солнце 15 лет светит неправильно из-за ошибки в коде, но фанат уже исправил её модом.
2 Xiaomi за 32 дня выпустила 10 000 электромобилей SU7, планирует в этом году поставить 100 000 и хочет выйти на мировой рынок. Tesla за 1 квартал выпустили 433 тыс и продали 386 тыс авто. При пересчете на 32 дня - выпустили 48 тыс и продали 43 тыс авто.
3 GitHub представила AI-платформу GitHub Copilot Workspace для ускорения работы программистов, интегрированную в GitHub Copilot, с поддержкой проектов от идеи до кода.
4 OpenAI запустила функцию памяти для ChatGPT, позволяющую чат-боту запоминать запросы, подсказки и другие настройки, чтобы улучшить ответы и упростить работу пользователей.
5 Boston Dynamics представила мохнатого робота-собаку Sparkles на базе Spot, предназначенного для сфер искусства и развлечений, который способен выполнять сложные движения под музыку и в обход препятствий. (обшили робота мехом, ждем новых фурри))
6 Microsoft Edge обновил поддержку высококонтрастных тем Windows, перейдя с устаревших функций CSS на новый кросс-браузерный стандарт.
🌐 Искусственный интеллект и гонка технологических гигантов! 🧠
В современной сфере генеративного искусственного интеллекта 🧠 преобладание принадлежит модели GPT-4, разработанной компанией OpenAI 🏭. Тем не менее, нарастающая конкуренция со стороны таких проектов, как Claude от Anthropic и Llama от Meta, обладающих открытым исходным кодом 👾, активизирует дискуссии относительно будущего развития флагманских языковых моделей OpenAI. В то время как общественность с интересом ожидает анонса GPT-5 🚀, предполагаемого к выпуску в 2024 году, эксперты предупреждают о возможных задержках связанных с необходимостью значительных инвестиций в ресурсы 💰.
По мнению Дэна Хендрикса, директора Центра безопасности ИИ, каждое новое поколение модели GPT требует существенного увеличения вычислительных мощностей 💪. Переход от четвертой к пятой версии предполагает увеличение необходимых ресурсов в сто раз, что эквивалентно круглосуточной работе миллиона графических процессоров H100 на протяжении трех месяцев 🕒.
Дарио Амодеи, генеральный директор Anthropic, подтверждает эти выводы, указывая на текущие затраты на обучение языковых моделей, составляющие около $1 млрд, и прогнозируя их рост до $5-10 млрд к 2025 году 🔝.
Также стоит отметить, что растущие потребности в вычислительных мощностях сопровождаются увеличением энергопотребления 🔌. Прогнозируется, что в 2027 году глобальное энергопотребление центрами обработки данных может достичь 85-134 ТВтч, что подчеркивает необходимость поиска более эффективных методов обучения моделей 💡.
В этом контексте эксперты высказывают предположение о том, что для сохранения конкурентных преимуществ OpenAI может потребоваться оптимизация процесса обучения, который в настоящее время зависит от обширных наборов данных, собранных из человеческих диалогов 🗣️. Это может привести к разработке промежуточной версии модели, GPT-4.5, вместо прямого перехода к GPT-5.
Гендиректор Nvidia Дженсен Хуанг (Jensen Huang) лично доставил первый ускоритель DGX H200 в офис компании OpenAI в Сан-Франциско, подчеркнув тесную связь между двумя гигантами в отрасли искусственного интеллекта.
Nvidia доставили новенький суперкомпьютер Сэму Альтману. Это первая модель DGX H200 — равных ему по мощности не было в истории.
Под капотом у монстра мощность в 1 экзафлопс и 144 ТБ памяти — он может выполнять квинтиллион (число с 18-ю нолями) операций в секунду. Это в 12 700 (!) раз мощнее RTX 4090 Ti.
На DGX H200 Альтман планирует создать GPT-5, и нам действительно страшно, что получится.